Why SetFit? Few-Shot Text Classification for Engineers Who Don't Have 10,000 Labeled Samples
by Sylvain Artois on Jan 10, 2026
- #setfit
- #nlp
- #text-classification
- #few-shot-learning
- #machine-learning

The Dataset Problem
So you need to classify text into categories. Maybe it’s support tickets, news articles, or customer feedback. You want something that fits your exact data, not a generic Kaggle dataset. And you have the data, but it’s not labeled. And labeling 10,000 examples is either expensive or painful. Probably both.
Traditional text classification with BERT-style models typically requires 1,000 to 10,000+ labeled examples per class to get decent performance. If you’re classifying into 20 categories, that’s potentially 200,000 labeled samples. Who’s going to label all that? Not me.
I’m building a news aggregation system that classifies French headlines into categories like “Géopolitique”, “Sport”, “Technologie” (have a look at afk.live if you’re curious). I can’t label thousands of headlines manually, and I don’t want to use Amazon Mechanical Turk. I need a solution that works with limited data.
After a lot of searching—probably during a conversation with Claude—I discovered SetFit. And that was it.
What is SetFit?
SetFit stands for Sentence Transformer Fine-tuning, which tells you a lot about what it does: it fine-tunes Sentence Transformers for classification tasks.
The Origin Story
SetFit was introduced in September 2022 in the paper “Efficient Few-Shot Learning Without Prompts”. It’s a collaboration between:
- Hugging Face: Lewis Tunstall (who also wrote the Natural Language Processing with Transformers book) and Nils Reimers (the creator of Sentence Transformers, now Director of ML at Cohere)
- Intel Labs: Moshe Wasserblat, Daniel Korat, and Oren Pereg from Intel’s NLP research group
The Key Claim
With only 8 labeled examples per class, SetFit achieves performance competitive with fine-tuning RoBERTa-Large on 3,000 examples. That’s not a typo. 8 examples versus 3,000.
On the RAFT benchmark (Real-world Annotated Few-shot Tasks), SetFit outperformed GPT-3 on 7 out of 11 tasks while being 1,600 times smaller.
How SetFit Works: The Two-Phase Architecture
The architecture is simple. Training happens in two phases:
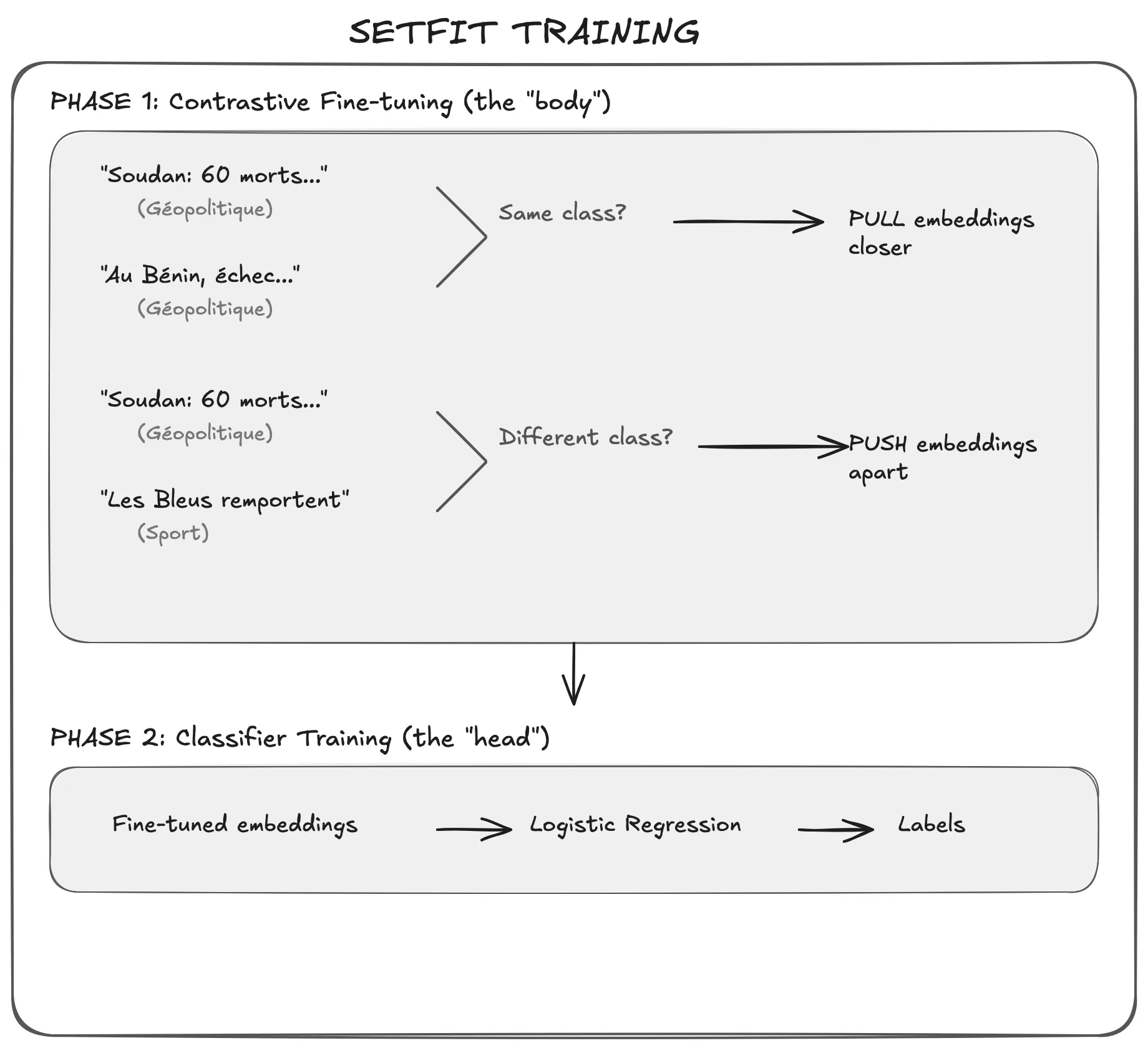
Phase 1: Teaching the Model What “Similar” Means
The first phase uses contrastive learning to fine-tune a pre-trained Sentence Transformer. The model learns to:
- Pull together embeddings of sentences from the same class
- Push apart embeddings of sentences from different classes
This is done using sentence pairs. Here’s why this is powerful: if you have 8 sentences per class, you can create many more training pairs. With 8 positive and 8 negative sentences, you get 28 positive pairs and 64 negative pairs. The number of unique training examples grows fast.
Phase 2: A Simple Classifier on Top
Once the Sentence Transformer has learned to create meaningful embeddings (where similar texts are close together), training a classifier becomes easy. By default, SetFit uses a scikit-learn Logistic Regression head. Nothing fancy, but it works.
In code, this looks like:
from setfit import SetFitModel, Trainer, TrainingArguments
# Initialize with a pre-trained Sentence Transformer
model = SetFitModel.from_pretrained(
"dangvantuan/sentence-camembert-large", # French language model
labels=["Géopolitique", "Sport", "Technologie", ...]
)
# Training arguments
args = TrainingArguments(
batch_size=16,
num_epochs=1, # Usually just 1 epoch is enough
num_iterations=5, # Number of text pairs per class
sampling_strategy="oversampling"
)
# Train
trainer = Trainer(model=model, args=args, train_dataset=train_dataset)
trainer.train()That’s it. The framework handles the pair generation and two-phase training automatically.
Understanding Siamese Networks and Contrastive Learning
If “contrastive learning” and “Siamese networks” sound intimidating—I was confused too at first—let me break them down.
Siamese Networks: Twin Neural Networks
A Siamese network is simply two identical neural networks that share the same weights. Think of them as twins processing two inputs at the same time.
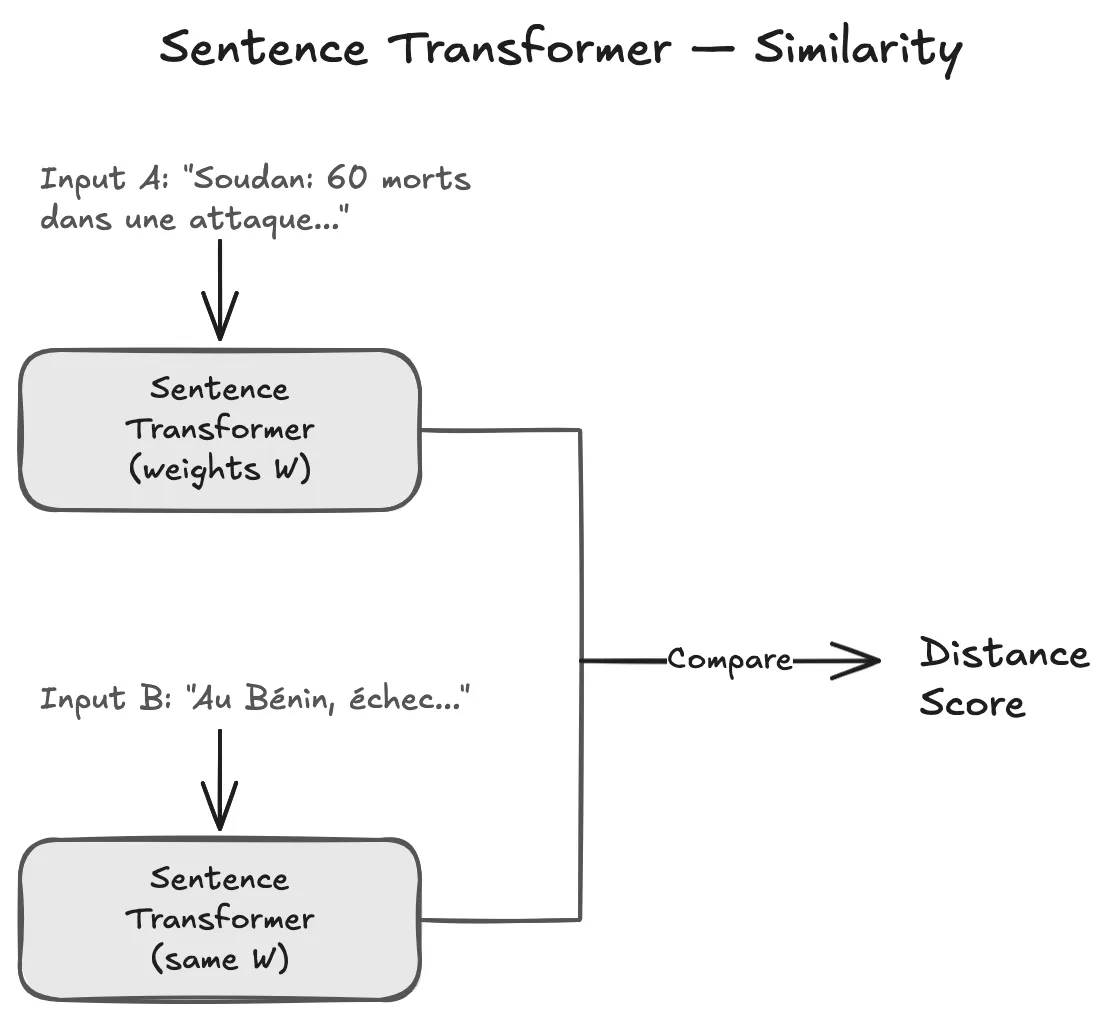
Both sentences pass through the exact same model (shared weights). The outputs are two vectors (embeddings), and we measure how close or far apart they are.
Why Share Weights?
- Fewer parameters: One model instead of two means faster training
- Consistency: Similar inputs produce similar outputs because they’re processed the same way
- Comparability: The embeddings live in the same vector space, so distances are meaningful
Contrastive Learning: Learning by Comparison
The core idea is simple: learn what makes things similar or different by comparing pairs.
Let me show you with real headlines from my French news dataset:
Positive pair (same category “Géopolitique”):
- “Soudan: 60 morts dans une attaque de drone à el-Facher”
- “Au Bénin, échec d’une tentative de coup d’Etat contre le président Patrice Talon”
The model should learn to place these close together in the embedding space.
Negative pair (different categories):
- “Soudan: 60 morts dans une attaque de drone à el-Facher” (Géopolitique)
- “Les Bleus remportent le match contre l’Italie” (Sport)
The model should push these far apart.
The Cosine Similarity Loss
SetFit uses cosine similarity to measure how close two embeddings are. Values range from -1 (opposite) to 1 (identical).
Cosine Similarity
│
1.0 ├─── Perfect match (same direction)
│
0.0 ├─── Orthogonal (unrelated)
│
-1.0 ├─── Opposite (completely different)
│During training:
- Positive pairs: The loss penalizes low cosine similarity (push toward 1.0)
- Negative pairs: The loss penalizes high cosine similarity (push toward 0.0 or below)
Why SetFit Over Traditional Approaches?
Dataset Size: The Main Advantage
| Approach | Examples per Class | Notes |
|---|---|---|
| Traditional BERT fine-tuning | 1,000 - 10,000+ | Requires large labeled datasets |
| PET (Pattern-Exploiting Training) | 10 - 100 | Requires handcrafted prompts |
| GPT-3/4 prompting | 0 - 10 | Expensive API calls, prompt engineering |
| SetFit | 8 - 50 | No prompts, fast training, runs locally |
Training Speed and Cost
Here’s what I see in production on my Dell G16 with an RTX 4070 (a mid-range gaming laptop, self-hosted inference):
| Operation | Headlines | Time | Speed |
|---|---|---|---|
| Classification | 577 | ~0.5s | ~1,150/sec |
| Model loading | - | ~2.5s | - |
| Full batch (load + classify + DB update) | 577 | ~8s | - |
For comparison, from the original paper:
| Model | Hardware | Training Time | Cost (approx.) |
|---|---|---|---|
| SetFit | NVIDIA V100 | ~30 seconds | ~$0.025 |
| T-Few 3B | NVIDIA A100 | ~11 minutes | ~$0.70 |
That’s 28x cheaper and much faster.
No Prompts Required
Unlike PET or GPT-3 prompting, SetFit doesn’t require you to craft clever prompts. You just provide labeled examples, and it figures out the rest.
This matters because:
- Prompt engineering is hard and requires experimentation
- Prompts are fragile - small changes can change results a lot
- Different languages need different prompts - SetFit just needs a multilingual Sentence Transformer
When Should You Use SetFit?
In theory, SetFit is the right tool when you have:
- Limited labeled data: You have 10-100 examples per class, not thousands
- Multilingual projects: Just swap the base Sentence Transformer model
- Fast prototyping needs: Train a classifier in under a minute
- Production constraints: Small model size, fast inference, runs locally
- Privacy-sensitive data: No need to send data to external APIs
The SetFit Ecosystem
SetFit has grown into a mature library with good documentation and community support:
Official Resources
- Documentation: huggingface.co/docs/setfit
- GitHub: github.com/huggingface/setfit
- Original Paper: arxiv.org/abs/2209.11055
- Hugging Face Blog: huggingface.co/blog/setfit
- Few-Shot Learning in Production: A workshop by Hugging Face and Intel covering SetFit, model compression, and deployment (1h22m)
Community
The SetFit organization on Hugging Face hosts hundreds of pre-trained models for various tasks and languages. With ~250,000 downloads per month, you’re not alone.
What’s Next in This Series
This article covered the “why” and “what” of SetFit. In the next articles, I’ll go into the practical “how”.
But first, why SetFit in the AFK data pipeline? I have two main goals:
- Pre-process headlines before BERTopic clustering: categorize them first so I can adjust UMAP and HDBScan settings based on each category’s semantic field
- Implement an editorial policy: filter headlines by category to control what appears on the site
You’ll see that SetFit alone is not a magic tool that can handle everything. But it’s a useful filter in building the pipeline.
Article 2: Building a SetFit Dataset: The Taxonomy
- How to structure your taxonomy
- Labeling strategies
- Dataset preparation for SetFit
This article is part of my journey learning ML as a senior engineer without a data science background. I’m documenting what I learn, including the mistakes, because the polished tutorials rarely show the messy reality of building ML systems.
References
- Tunstall, L., Reimers, N., Jo, U.E.S., Bates, L., Korat, D., Wasserblat, M., & Pereg, O. (2022). Efficient Few-Shot Learning Without Prompts. arXiv:2209.11055.
- Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. EMNLP 2019.
- Schick, T., & Schütze, H. (2020). Exploiting Cloze Questions for Few-Shot Text Classification and Natural Language Inference. arXiv:2001.07676.
- Alex, N., et al. (2021). RAFT: A Real-World Few-Shot Text Classification Benchmark. NeurIPS 2021.